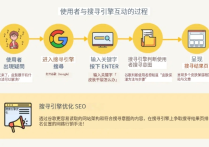
谷歌SEO怎么处理碎片化信息呢?
本来想从算法角度输出一下文章导出链接(即给别人做外链)的必要性,但今天事情真的好多,好几个事情等着交付。所以就拿一个上周在群里分享过的话题出来聊聊,也就是谷歌SEO怎么处理碎片化信息。
一般而言,平哥SEO的信息源有很多,比如专业的论坛、博客、Newsletter、RSS的订阅源、付费渠道,等等。要知道这些信息真的非常杂,且这些信息中也有不少垃圾。所以从这个角度出发,好好设计下「碎片化信息」的消化流程就比较重要。
我的做法是,将各个渠道的信息统一归集起来,然后利用碎片化的时间去快速筛选。在筛选的过程中,碰到有价值的内容后再单独拎出来。且整个过程尽量做到高效,至于那种一眼扫过去就能明白的,快速划过去不要浪费时间。
剩下的就是一些需要点时间处理的内容了,这主要也有两块。一是需要时间阅读的,如果能当场读完,那就立马消化掉,不要等后面再来翻这些内容。二是需要时间消化的(比如那些最新的知识、最新的动态),那就将这些信息打上标签,存到软件里面,等专门找一块时间出来消化。
当然,这些「存到软件」的步骤也有不少讲究。其一是信息的初加工,其二是储存软件的选择。
信息初加工这块,我的习惯是对于每一条需要消化的信息,写一段50-100字左右的描述,讲清楚这条信息是什么、里面主要的逻辑结构是什么、可以怎么用,以及这条信息的价值评估。
这段描述文字写完后,剩下的就是给信息打个标签,然后扔到相应软件里。
对于存储软件的选择,不同人可能有不同的标准吧,比如有小伙伴喜欢用Excel这种传统办公软件,或者是Notion这种新型的文档协作软件。但对于这些碎片的、不成体系的内容,我一般都是扔到「电报」里去。
主要还是因为这款软件的隐私保护做的还可以,且多端同步,信息的同步都很不错。另外还有一个点,就是可以很方便的给信息作标签,便于后续的搜索。且对于那些占据储存空间很大的素材,也完全可以扔到这个软件中去,将其当作自己的私人网盘来使用。
以上便是我已经实践了很久的消化流程,后续如果空闲时间多点,我会考虑写个机器人,将AI的能力引入进来,协助我做信息整理这部分工作。也就是将一个链接扔进去后,机器人能帮我自动分析出链接中的文本内容,讲的是什么东西,并把信息大纲整理出来。这样整体的消化效率便能大大提升了,也好玩了不少。