Google 检索、索引、排名的原理规则是什么?
Google SEO中的爬取、索引跟搜索引擎排名,分别是什么意思呢?在学习SEO之前,必定要先了解一下谷歌搜索引擎的运作方式。从你的网站文章发布的那一瞬间,你的文章网址会经历:被找到、被爬取(检索)、被索引,然后才能出现在Google搜索引擎里面并且加入Google搜索结果的排名。上面的这个过程,从网址被找到,一直到被爬取跟索引,然后再到开始在Google搜索引擎排名,这就是Google搜索引擎的运作方式。

了解Google搜索引擎的运作方式非常重要,因为Google在检索、索引到搜索引擎排名的过程当中,有非常多的SEO知识在里面。例如Google检索时是检索哪些东西?Google索引时是索引哪些东西?当你的文章开始加入Google搜索引擎排名,文章的初始排名是怎么决定的?这中间隐含大量的SEO知识跟排名要素(Ranking factors)在里面。
如果你还不知道SEO中的爬取、索引跟排名的整个过程以及运作方式,本篇文章平哥SEO会做一个完整的介绍,让你了解Google搜索引擎的基本运作原理。
Google搜索引擎的爬取、索引跟排名,是什么?
当一个新的网址出现的时候,它一定会经历「被找到」的过程,所以虽然我们可以将Google搜索引擎的运作方式分成:检索(爬取)、索引跟排名,但其实前面还有一个「找到」网址的过程。
这里将网址被找到、爬取(检索)、索引跟排名,简单说明如下。
Google找到网址
当一个新页面出现时,Google的爬虫必然会先找到该网址,并且将该网址加入网址库,然后比对一下网址库里面是不是有这条网址,如果确认是新的网址,就会安爬时间去检索(爬取)。
在Google Search Console里面的「涵盖范围」功能当中,你也可以清楚看到一条网址它的「发现方式」,可能是从你提交的Sitemap当中发现的,也有可能是从别的网址找到你这条链接的。

Google爬存(检索)
当有新的网址出现在Google数据库中的网址库之后,就会安排时间去检索,其实「检索」是官方的名称,熊猫先生也比较喜欢用「检索」这个词,不过在SEO界里,检索很常被称作「爬取」,你只要知道它们指的都是Crawl就可以了。无论是爬取还是检索,都是指Crawl。
在Google search Console里面的「涵盖范围」功能,你也可以很清楚的看到关于「检索」的讯息。下面有两个重要的观念:
是否允许检索:如果显示否,那么该网址可能是出现在robots.txt,也就是网站主在robots.txt这个档案当中不允许检索这条网址。
是否允许编入索引:如果显示否,代表该网址很可能有noindex中继标记,所以才会出现不允许给页面被索引的讯息。
这里特别说明:robots.txt是用来告诉搜索引擎不要爬取特定页面,而noindex则是用来告诉搜索引擎不要索引特定页面。

当爬虫程序爬取了你的页面之后,会将整个网页的信息压缩并存入数据库里面,在「检索」阶段,Google存入数据库的信息就像是用户打开浏览器时得到的HTML网页,一直要到「索引」阶段,才会将检索的资料去芜存菁,只索引重要的信息。
Google索引
Google在索引阶段要处理的东西很多,因为Google不可能将你网页上全部的HTML源代码,或是各种文字都存入数据库,这样数据库会变得过于庞大而没有效益,所以Google「索引」阶段肯定只会索引重要的东西,而这些东西会影响你这个网址之后在某个「关键字」的排名。
那么,Google到底索引了哪些东西?常见的会被索引的信息包含如下:
1.重要的关键词
Google是如何提取页面中的关键词,这个只有Google内部人员才知道,通常提取的关键词可能也有10个以上,而且每个被提取出来的关键词,其权重加总之后通常不一样。
唯一可以肯定的是,页面中的Meta title、H1、H2肯定是重点。这也是为什么很多SEO人都强调关键词要出现在标题或是H2里面的重要性。
2.链接与锚文字
页面中的链接与锚点文字也是会被索引的东西。
3.图片Alt text
图片当中的alt text,也是会被提取的文字。
4.关键字的文字大小(font-size)
根据Google的Pagerank原始文件,有特别提到,Google会提取关键字大约的文字大小,文字越大通常重要性也越高。
5.文章中的粗体字
粗体字通常是或是这样的标签,粗体字也会是被记录的信息。
6.关键字在页面中的位置
关键词出现在页面中的位置,也是会被记录在索引数据库里面。
除了上面提到的这几点资讯以外,Google肯定还索引了其它东西,但很多东西是我们不知道的,这些被用来索引的东西,通常也可以视为SEO排名要素(Ranking factors)。
Google排名
当你的某个页面网址被索引之后,基本上就已经可以出现在Google搜索引擎里面并加入排名了。Google号称有两百多条SEO排名要素,这200多条排名要素都会在整个SEO关键词排名中起到一定程度的作用,有些影响作用很大(例如反向链接),有些影响作用比较小(例如关键字出现在URL网址里)。
Google搜索引擎的运作原理
从上面你应该已经了解到,Google搜索引擎的运作原理,基本上就是四个阶段:网址被找到、网址被爬取、网址被索引跟网址被排名。简单的讲,谷歌搜索引擎的运作原理有这四个阶段。
网址被找到
爬取(又称检索)
索引(又称收录)
排名
从事SEO工作的人必须非常了解这四个阶段的各种SEO细节,你才能从中找到一些问题,例如以下几个重点:
一个网址如果迟迟没有被检索,那会是什么原因?
一个网址如果迟迟没有被索引,那会是什么原因?
关于Google搜索引擎的运作原理,其实Matt Cutts在Youtube网站上有一段视频,讲解的非常清楚,这段视频建议一定要看。Matt Cutts的这段视频清楚的解释了:Google爬取、索引跟排名的过程。
在Google搜索引擎的关键词排名的过程中,除了参考Google索引中的资料,另外还有Pagerank跟200多条SEO排名要素(注意:Google索引中的资料,有些本身就是排名要素)。
除了上面这只影片之外,Matt Cutts在另外一只影片,也提到了Google搜索引擎的运作方式,下面这只视频也建议一定要看,你会对Google搜索引擎的运作原理与搜索引擎排名有更深的理解。
Google正向索引与倒序索引
在Google的「索引」过程当中,有件事特别重要,那就是「正向索引」跟「倒序索引」,如果不是具有理工背景的人,可能很难理解这两个概念。
下面分别解释Google索引中的正向索引与倒序索引。
正向索引
每个网址都被指派一个独一无二的DocID,这个数据表中储存着该网页的重要关键词。
倒序索引
Google透过正向索引的数据,改变其索引方式,换成以关键字为键值的数据表,每个数据列都有一个KeywordID,每个KeywordID里面包含着重要的网址(DocID)。
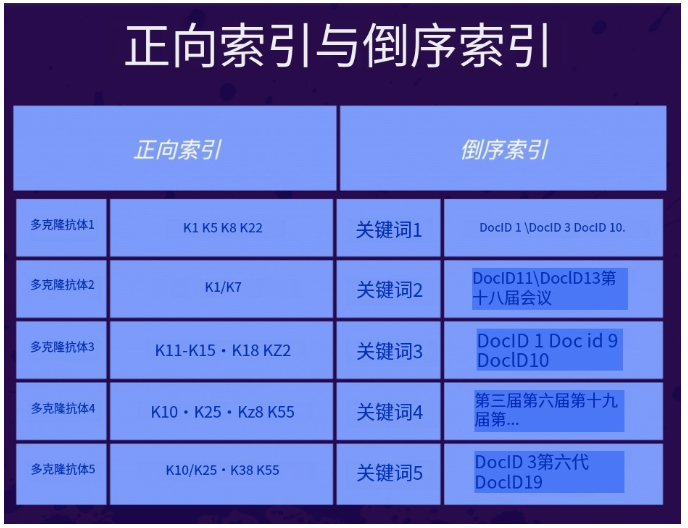
当用户在Google搜索关键词的时候,Google会去调用倒序索引里面的资料,这样查询速度才会快,因为如果使用正向索引资料表,这样查询会变得超级慢,因为网路上有上百亿个网页,这计算时间实在太过庞大,这也是为什么原本的正向索引必须改成倒序索引的原因。